1. はじめに
2024 年 5 月 14 日、OpenAI 社から新たな生成 AI「GPT-4o」が発表され、世界に大きな衝撃を与えました。これまでの GPT-4 よりも性能を向上させただけでなく1、音声や画像のリアルタイム処理も実現し、さらに応答速度が大幅に速くなりました。「ついにシンギュラリティが来てしまったか」「まるで SF の世界を生きているような感覚だ」という感想も見受けられました。
しかし、いくら生成 AI とはいえ、競技プログラミングの問題を解くのは非常に難しいです。なぜなら競技プログラミングでは、問題文を理解する能力、プログラムを実装する能力だけでなく、より速く答えを求められる解法 (アルゴリズム) を考える能力も要求されるからです。もし ChatGPT が競技プログラミングを出来るようになれば他のあらゆるタスクをこなせるだろう、と考える人もいます。
それでは、現代最強の汎用型生成 AI である GPT-4o は、果たしてどれくらい競技プログラミングの問題を解くことができるのでしょうか。本記事では、国内トップレベルの競技プログラマーである筆者が、その実験結果について記したいと思います。
目次
- はじめに
- 競技プログラミングとは
- 実験方法
- 実験結果
- まとめと注意点
- おわりに

2. 競技プログラミングとは
まずは競技プログラミングを知らない方のために、競技プログラミング (競プロ) とは一体どういうものかを説明します。知っている方は読み飛ばして構いません。
競技プログラミングは、プログラミングの問題を解く大会です。プログラミングの大会と聞くと、皆さんの多くはアプリ開発やロボット製作などを思い浮かべると思いますが、競プロはそれとは違います。いくつかの問題が出題され、2 時間といった制限時間内に何問解けるかを競う大会です。数学の試験のプログラミング版だと考えるとわかりやすいでしょう。
問題例 1
それでは、競プロではどんな問題が出題されるのでしょうか。問題例として、以下が挙げられます。
リンゴが 3 個、ミカンが N 個ある。ミカンの個数が入力として与えられるので、果物の合計個数を出力するプログラムを作成せよ。ただし N は 1 以上 100 以下である。
この問題は非常に簡単で、たとえば代表的なプログラミング言語 Python を使った場合、次のようなプログラムを書くと正解となります。
N = int(input()) print(N + 3)
問題例 2
しかし、もう少し難しい問題になると、プログラムの実行時間も要求されます。例として、以下の問題を考えてみましょう。
足す数・足される数が 1 以上 N 以下、答えが M 以下となる足し算はいくつあるか。ただし N と M は 30 万以下である。
たとえば N=3, M=5 の場合、1+1=2、1+2=3、1+3=4、2+1=3、2+2=4、2+3=5、3+1=4、3+2=5 の 8 個の足し算があるため、答えは 8 である。
自然にプログラムを書くと、以下のようになります。
N = int(input()) M = int(input()) Answer = 0 for i in range(1, N+1): # 足す数 for j in range(1, N+1): # 足される数 if i + j <= M: Answer += 1 print(Answer)
このプログラムは確かに正しい答えを出力します。
しかし、このプログラムに N = 300000, M = 300000 を入力して実行してみましょう。残念ながら 1 分経っても答えが出力されず、不正解となってしまいます。
なぜなら、二重の for 文を使っているため 30 万掛ける 30 万、つまり 900 億回の計算を行っているからです。そして 900 億回の計算は、現代の PC をもっててしても一瞬では終わらない計算だからです。2
そこで、少しプログラムを変えて以下のようにしてみましょう。
N = int(input()) M = int(input()) Answer = 0 for i in range(1, N+1): # 足す数 Answer += max(0, min(N, M-i)) print(Answer)
二重の for 文が一重の for 文に変わったため、実行時間が大幅に短くなり、これでようやく正解となりました。
このように競プロでは、プログラムを実装する能力だけでなく、「どうやったらより速く答えを出せるのか」を考える能力が必要であるため、非常に難しい頭脳勝負となっています。
AtCoder について
次に、日本を代表する競プロの大会である「AtCoder」について紹介します。
AtCoder は国内最大規模のコンテストサイトであり、毎週土曜日か日曜日の 21 時から、2 時間程度のコンテストがオンラインで開催されます。日本国内だけで 5000 人、海外を含めると 1 万人以上が同時に参加し、AtCoder の登録者数は 50 万人を超える規模となっています。
また、AtCoder のコンテストに参加すると、成績に応じてレーティングが付けられます。レーティングは強さの証明となるため、技術系アルバイトや就職・転職などで用いられることもあります。
AtCoder は日本語版の問題文も提供されており、初心者に比較的親切であるため、この記事で競プロに興味を持った方はぜひ AtCoder を始めましょう。

3. 実験方法
それでは本題に戻ります。
今回は ChatGPT の性能を調べるため、ChatGPT に競プロの問題を 10 問出題しました。ここで問題は難易度順に並べられており、検索やブラウジング機能、学習データによる利益を一切封じるため、すべて筆者オリジナルの問題にしました。3
また、ChatGPT の性能を最大限発揮させるため、問題文は学習データの多い英語版で提供することにしました。ここで、筆者は英語がそれほど得意ではないため、無料版 Grammarly による添削を行った後の問題文を提供しました。
さらに、問題文には AtCoder と同様、制約・入力形式・出力形式・入出力例を付けることにしました。つまり、以下のような形式で問題文が与えられます。
# Problem Statement There are 3 apples and N bananas. Write a program that prints the total number of fruits. # Constraints - 1 <= N <= 100 - N is an integer # Input N # Output Print the answer. # Sample Input 7 # Sample Output 10
そして、ChatGPT が置かれている状況をプロンプトに入れると性能が上がるという情報もあるため、今回は以下のようなプロンプトを与えることにしました。
You are one of the top competitive programmers in the world. Write a code to solve the following problem. Any programming language is allowed. --- (問題文をここに貼り付ける)
フィードバック
続いて、ChatGPT が回答を提出した後、どのような形式でフィードバックを与えるかについて説明します。
原則以下の 6 通りのいずれかのフィードバックを与え、これらのフィードバックのみ (= 原則人間の手助け無し) で正解にたどり着いたものだけに得点を与えます。3 回目の提出で正解にたどり着けなかったものは不正解とみなします。
| ケース | フィードバック |
|---|---|
| コンパイルが通らない場合 | Unfortunately, your solution is judged as Compile Error. Please fix your solution. |
| 入力例で不正解となった場合 | Unfortunately, your solution does not output the correct answer for Sample Input. Please fix your solution. |
| その他のケースで不正解となった場合 | Unfortunately, your solution judged as Wrong Answer. Please fix your solution. |
| 実行時エラーとなった場合 | Unfortunately, your solution judged as Runtime Error. Please fix your solution. |
| 実行時間制限超過となった場合 | Unfortunately, your solution judged as Time Limit Exceeded. Please improve time complexity of your solution. |
| 正解となった場合 | Congratulations! You submitted a correct solution. |
それでは、果たして ChatGPT は 10 問中何問を解くことができるのでしょうか。いよいよお待ちかねの結果発表です。
4. 実験結果
まずは 1 問目から順番に行きたいと思います。
第 1 問
# Problem Statement Mr.LLM bought N items in a supermarket. The price of i-th item was A[i] dollars. Write a program that outputs the total price. # Constraints - 1 <= N <= 100 - 1 <= A[i] <= 100 (1 <= i <= N) - All input values are integer # Input N A[1] A[2] A[3] ... A[N] # Output Print the answer. # Sample Input 1 5 3 1 4 1 5 # Sample Output 1 14
日本語の問題文は次のようになります。
LLM さんはスーパーで N 個の品物を買った。i 個目の品物の価格は A[i] ドルだった。合計価格を出力せよ。
配列を入力して足し算をするだけなので簡単ですね。現役のプログラマなら絶対解かなければならない問題です。もちろん ChatGPT も簡単に解くことが出来ました。
def total_price(): # Read input N = int(input()) A = list(map(int, input().split())) # Calculate the total price total = sum(A) # Output the result print(total) # Call the function to execute total_price()
第 2 問
# Problem Statement There is a string S of length N. All characters in string S are from 'a' to 'z'. A string is good if the following two conditions are satisfied: 1. There are exactly 5 kinds of character 2. Every two adjacent characters are different Write a program that outputs whether the given string S is good or not. # Constraints - 1 <= N <= 100 # Input N S # Output If string S is good, print 'Yes'. Otherwise, print 'No'. # Sample Input 11 abracadabra # Sample Output Yes
日本語の問題文は次のようになります。
N 文字の英小文字からなる文字列 S が与えられる。文字列が以下の 2 つの条件を満たすとき、良い文字列という。
- ちょうど 5 種類の文字がある。
- どの隣接する 2 文字も異なる文字である
1 問目よりは少し問題設定が複雑になりましたが、この難易度であれば AtCoder 参加者の 80% 以上が解くことができるでしょう。もちろん ChatGPT も簡単に解くことが出来ました。
def is_good_string(): # Read input N = int(input()) S = input().strip() # Check if the string has exactly 5 kinds of characters unique_chars = set(S) if len(unique_chars) != 5: print("No") return # Check if every two adjacent characters are different for i in range(1, N): if S[i] == S[i - 1]: print("No") return # If both conditions are satisfied print("Yes") # Call the function to execute is_good_string()
第 3 問
# Problem Statement There is a grid with R rows and C columns. The cell on the i-th row and the j-th column is denoted as cell (i, j). For each (i, j) (1 <= i <= R, 1 <= j <= C), cell (i, j) is colored black if A[i][j]=1, and colored white if A[i][j]=0. Mr.LLM wants to know whether 4*4 black subgrid exists in the grid. More formally, he wants to know whether there exists a value (a, b) (1 <= a <= R-3, 1 <= b <= C-3) that all cells (i, j) (a <= i <= a+3, b <= j <= b+3) are black. Write a program that outputs the answer. # Constraints - 4 <= R <= 100 - 4 <= C <= 100 - 0 <= A[i][j] <= 1 (1 <= i <= H, 1 <= j <= W) - All input values are integer # Input R C A[1][1] A[1][2] A[1][3] ... A[1][C] A[2][1] A[2][2] A[2][3] ... A[2][C] : A[R][1] A[R][2] A[R][3] ... A[R][C] # Output If 4*4 subgrid exists, print 'Yes'. Otherwise, print 'No'. # Sample Input 5 5 1 1 0 1 0 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1 0 1 1 1 1 # Sample Output Yes
日本語の問題文は以下のようになります。
R 行 C 列のマス目が与えられる。各マスは黒か白で塗られている。全部黒で塗られている 4×4 の領域があるかを判定せよ。
少し難しくなってきた人も多いかもしれませんが、4×4 の領域を全部調べるという方法で解くことができます。たとえば下図の例の場合、以下の 4 通りを調べると答えを出すことができます。一番最後の 4 番目が条件を満たしているため、答えは Yes です。
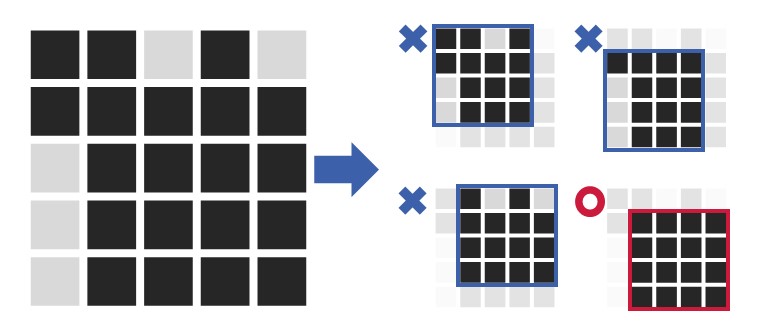
それでは、ChatGPT はこの問題を解くことができるのでしょうか。4 重の for 文などの複雑な実装が要求されますが、余裕で解くことが出来ました。この時点で、AtCoder 参加者の約 25% を上回っています。
def find_black_subgrid(): # Read the dimensions of the grid R, C = map(int, input().split()) # Read the grid A = [list(map(int, input().split())) for _ in range(R)] # Check for a 4x4 subgrid of all black cells for i in range(R - 3): for j in range(C - 3): all_black = True for x in range(i, i + 4): for y in range(j, j + 4): if A[x][y] != 1: all_black = False break if not all_black: break if all_black: print("Yes") return print("No") # Call the function to execute find_black_subgrid()
第 4 問
# Problem Statement
An integer is good if it is multiple of 2024 and the sum of digits is less than or equal to K.
Write a program that outputs how many integers between 1 and N are good.
# Constraints
- 1 <= K <= 100
- 1 <= N <= 10^{10}
- All input values are integer
# Input
K N
# Output
Print the answer.
# Sample Input
20 10000
# Sample Output
3
日本語の問題文は以下のようになります。
2024 の倍数かつ各位の数字の和が K 以下であるものを「良い整数」と呼ぶ。1 以上 N 以下の整数の中で、良い整数はいくつあるか。
この問題を解く最も単純な方法として、1 が良い整数か、2 が良い整数か、3 が良い整数か、のように順番に調べていく方法があります。この方法を Python で実装すると以下のようになります。
# sumdigit は各位の数字の和を返す関数とする。ここでは省略する。 K, N = map(int, input().split()) Answer = 0 for i in range(1, N+1): if N % 2024 == 0 and sumdigit(N) <= K Answer += 1 print(Answer)
しかし、本問題の制約は「N が 100 億以下」であるため、この方法だと最大 100 億回以上の計算を行うことになり、実行に時間がかかってしまいます。このままでは正解できません。
そこで、2024 の倍数だけを調べるという工夫をすることで、実行時間を大幅に削減することができます。つまり、2024 は良い整数か、4048 は良い整数か、6072 は良い整数か、のように調べるということです。この工夫を思いつけるかどうかが、本問題を解く最大の鍵となります。
それでは、ChatGPT はこの問題を解けるのでしょうか。以下のように、工夫した解法でしっかり解いてきました。
def count_good_integers(): import sys input = sys.stdin.read data = input().split() K = int(data[0]) N = int(data[1]) def sum_of_digits(x): return sum(int(digit) for digit in str(x)) count = 0 for num in range(2024, N + 1, 2024): if sum_of_digits(num) <= K: count += 1 print(count) # Call the function to execute count_good_integers()
第 5 問
# Problem Statement
You are given an integer N. Write a program that outputs an array A = {A[1], A[2], ..., A[N]} (length is N) which satisfies the following conditions:
1. A[1] < A[2] < ... < A[N]
2. For each i (1 <= i <= N), A[i] is an integer between 1 and 1000000.
3. For each i (1 <= i <= N-1), A[i+1] is divisible by A[i].
4. For each i (1 <= i <= N-2), A[i+2] is divisible by A[i]+A[i+1].
# Constraints
- 1 <= N <= 6
- N is an integer
# Input
N
# Output
Print the answer in the following format.
A[1] A[2] ... A[N]
If there are multiple answer, any of them is regarded as correct.
# Sample Input
4
# Sample Output
5 10 30 120
日本語の問題文は以下のようになります。
整数 N が与えられる。次の条件を満たす数列 A[1], A[2], ..., A[N] を 1 つ作れ。
- A[1] < A[2] < ... < A[N]
- A[i] は 1 以上 100 万以下
- どの i (1 <= i <= N-1) についても、A[i+1] は A[i] で割り切れる
- どの i (1 <= i <= N-2) についても、A[i+2] は A[i]+A[i+1] で割り切れる
この問題は、実際に手を動かして考える必要があるという点で難しいですが、前から順に考えていけば数分で解くことができます。たとえば N=4 の場合を考えてみましょう。
- A[1] について:適当に 5 とします。
- A[2] について:A[1]=5 より 5 の倍数でなければならないので、適当に 10 とします。
- A[3] について:A[1]=5, A[2]=10 より 10 と 15 の倍数なので、30 とします。
- A[4] について:A[2]=10, A[3]=30 より 30 と 40 の倍数なので、120 とします。
- これで正しい数列 [5, 10, 30, 120] を得ることができました。
それでは、ChatGPT はこの問題を解くことができるのでしょうか。なんと、ここで初めて間違ったプログラムを提出しました! 入力例の N=4 では [2, 6, 12, 48] を出力しましたが、残念ながら 48 は 6+12=18 の倍数ではないため、条件を満たしていません。
def generate_array(N): if N == 1: print(1) return elif N == 2: print(1, 2) return elif N == 3: print(1, 2, 6) return # Start with a small set of base values that satisfy the initial conditions A = [2, 6, 12] # Generate the rest of the values to satisfy the conditions for i in range(3, N): next_value = A[i-1] * (i + 1) A.append(next_value) # Output the generated array print(' '.join(map(str, A[:N]))) # Read input value N N = int(input().strip()) # Generate and print the array generate_array(N)
そこで、入力例で不正解であるということを ChatGPT に伝えたところ、今度はまったく別のプログラムを出してきました。しかし残念ながら、このプログラムは無限ループに陥ります。
その後も 2 回目のフィードバックを与えましたが、最後まで正解には至りませんでした。どうやら、ChatGPT は手を動かして考察しなければならない問題が苦手なようです。
def generate_array(N): if N == 1: print(1) return elif N == 2: print(1, 2) return elif N == 3: print(1, 2, 6) return # Start with a small set of base values that satisfy the initial conditions A = [1, 2, 6] # Generate the rest of the values to satisfy the conditions for i in range(3, N): next_value = A[i-2] + A[i-1] while next_value % A[i-1] != 0 or next_value % (A[i-2] + A[i-1]) != 0: next_value += A[i-1] A.append(next_value) # Output the generated array print(' '.join(map(str, A[:N]))) # Read input value N N = int(input().strip()) # Generate and print the array generate_array(N)
第 6 問
# Problem Statement In LLM High School, the exam result is graded on a scale of 0 to N as follows. - If the score of the exam was less than A[1] points, the grade will be 0. - If the score of the exam was between A[1] points and A[2]-1 points, the grade will be 1. - If the score of the exam was between A[2] points and A[3]-1 points, the grade will be 2. - If the score of the exam was between A[3] points and A[4]-1 points, the grade will be 3. - : - If the score of the exam was more than or equal to A[N] points, the grade will be N. Q students numbered from 1 to Q took the exam. The score of student i was S[i] points. Write a program that outputs the grade of each student. # Constraints - 1 <= N <= 200000 - 1 <= A[1] < A[2] < A[3] < ... < A[N] <= 1000000 - 1 <= Q <= 200000 - 1 <= S[i] <= 1000000 (1 <= i <= Q) - All input values are integer # Input N A[1] A[2] ... A[N] Q S[1] S[2] ... S[Q] # Output Print Q lines. In i-th line (1 <= i <= Q), print the grade for i-th student. # Sample Input 4 50 65 80 90 5 66 96 35 49 50 # Sample Output 2 4 0 0 1
日本語の問題文は以下のようになります。
LLM 高校では、以下のように 0 から N までの N+1 段階の評定が付けられる。
- 試験の点数が A[1] 点未満の場合、評定は「0」となる。
- 試験の点数が A[1] 点以上 A[2] 点未満の場合、評定は「1」となる。
- 試験の点数が A[2] 点以上 A[3] 点未満の場合、評定は「2」となる。
- :
- 試験の点数が A[N] 点以上の場合、評定は「N」となる。
Q 人の生徒が試験を受けた。各生徒の点数が与えられるので、各生徒の成績を出力せよ。
この問題の解答を自然に実装すると以下のようになります。しかし、このプログラムは二重の for 文を使っており、N×Q 回程度の計算が必要です。N, Q が両方上限の 20 万の場合は 400 億回となるため、実行に時間がかかってしまいます。
# Input N = int(input()) A = list(map(int, input().split())) Q = int(input()) S = list(map(int, input().split())) # Solve for score in S: # score は生徒の点数 grade = 0 for border in A: # border は評定が変わる基準 if score >= border: grade += 1 print(grade)
そこで二分探索 (Binary Search) という典型的な手法を使うと4、プログラムを高速化することができます。なお、一般に二分探索などの基本的な典型手法を知っているかどうかは、競技プログラミング初級者と中級者の分け目となるため、実力を測る上では非常に重要な問題です。
それでは、ChatGPT はこの問題を解くことができるのでしょうか。なんと、一発で二分探索を使った正しいプログラムを提出しました。流石です。
from bisect import bisect_right def main(): import sys input = sys.stdin.read data = input().split() idx = 0 # Read N N = int(data[idx]) idx += 1 # Read A A = list(map(int, data[idx:idx+N])) idx += N # Read Q Q = int(data[idx]) idx += 1 # Read S S = list(map(int, data[idx:idx+Q])) # Process each student's score and determine the grade results = [] for score in S: grade = bisect_right(A, score) results.append(grade) # Print results for result in results: print(result) if __name__ == "__main__": main()
第 7 問
# Problem Statement Mr.LLM finished the final exams, and the summer vacation of N days has started. However, he has to solve exactly M mathematics problems for homework. He decided to solve 0, 1, or 2 problems for each day, but he hasn't decided the number of problems to solve for each day. How many possible plans are there? For example, if N=2 and M=3, there are 2 possible plans. - Solve 1 problem on the first day, and solve 2 problems on the second day. - Solve 2 problems on the first day, and solve 1 problem on the second day. # Constraints - 1 <= N <= 30 - 1 <= M <= 2N - All input values are integer # Input N M # Output Print the answer. # Sample Input 2 3 # Sample Output 2
日本語の問題文は以下のようになります。
LLM 氏には N 日間の夏休みがあるが、宿題が出されて合計 M 問の数学の問題を解かなければならない。そこで彼は毎日 0, 1, 2 問のいずれかの問題を解くことに決めた。何通りの計画があるかを答えよ。
この問題を解く最も単純な方法は、宿題の解き方を全部調べることです。しかし、以下の樹形図を見ると分かる通り、制約の上限である N=30 の場合は全部で 3 の 30 乗通りを調べる必要があります。3 の 30 乗は 200 兆を超えますので、当然時間内には実行が終わりません。そこで動的計画法という典型手法を使うと、この問題を高速に解くことができます。
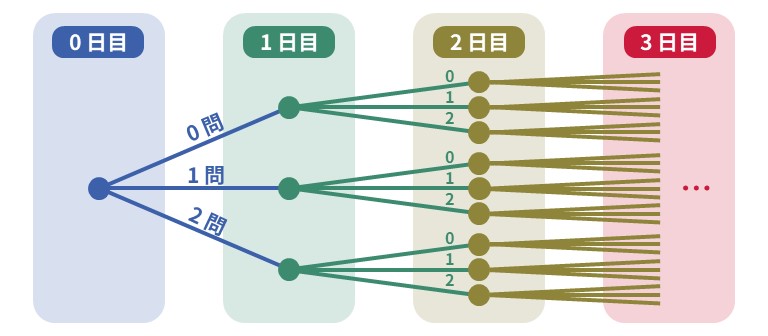
それでは、ChatGPT は動的計画法を理解しているのでしょうか。そして、この問題は動的計画法で解けるんだということがしっかり分かるのでしょうか。
プロンプトを入力した結果、動的計画法を用いた正しい解答を出してきました。どうやら ChatGPT は典型手法を用いた問題が比較的得意のようです。
def count_plans(N, M): # Initialize the DP table with all zeros dp = [[0] * (M + 1) for _ in range(N + 1)] # Base case: one way to assign 0 problems in 0 days dp[0][0] = 1 # Fill the DP table for i in range(1, N + 1): for j in range(M + 1): # If solving 0 problems on the i-th day dp[i][j] += dp[i-1][j] # If solving 1 problem on the i-th day if j >= 1: dp[i][j] += dp[i-1][j-1] # If solving 2 problems on the i-th day if j >= 2: dp[i][j] += dp[i-1][j-2] # The answer is the number of ways to distribute M problems over N days return dp[N][M] # Read input N, M = map(int, input().strip().split()) # Print the result print(count_plans(N, M))
第 8 問
# Problem Statement You are given two integers A and B. Write a program that checks whether 2^A is strictly larger than 10^B or not. # Constraints - 1 <= A <= 100000000 - 1 <= B <= 100000000 - All input values are integer - The relative error between 2^A and 10^B is more than 0.01 # Input A B # Output If 2^A is larger than 10^B, print 'Yes'. Otherwise, print 'No'. # Sample Input 10 3 # Sample Output Yes
日本語の問題文は以下のようになります。
2 の A 乗が 10 の B 乗より大きいかを判定せよ。
この問題を解く最も単純な方法は、以下のように単純に if 文を使って比較を行うことです。Python で実装すると以下のようになります。
# 2.0 ** A は 2 の A 乗を意味し、10.0 ** B は 10 の B 乗を意味する A, B = map(int, input().split()) if (2.0 ** A) > (10.0 ** B): print("Yes") else: print("No")
しかし、この方法では残念ながら不正解です。たとえば、A として 1 億、B として 1000 万を入力した場合、エラーが起こってしまいます。この理由は、計算の途中で非常に大きい数が出てしまい、オーバーフローを起こすからです。
たとえば A が制約の最大値である 1 億の場合を考えましょう。このとき、2 の A 乗は約 3000 万桁の数になります。しかし Python の一般的な浮動小数点型では、2 の 300 乗程度までしか表現することができないため、値を正しく表すことができず、実行時エラーとなってしまいます。このような現象はオーバーフローといい、競プロで注意すべきポイントの 1 つになっています。
それでは、ChatGPT は正しくプログラムを書けるのでしょうか。以下のように対数関数を使うことで、見事オーバーフローを回避しました。
import math def compare_exponents(A, B): # Calculate log(2) and log(10) using natural logarithms log2 = math.log(2) log10 = math.log(10) # Calculate A * log(2) and B * log(10) power_of_2 = A * log2 power_of_10 = B * log10 # Compare the two values if power_of_2 > power_of_10: print("Yes") else: print("No") # Read input A, B = map(int, input().strip().split()) # Perform the comparison compare_exponents(A, B)
さらに注目すべき部分は、以下の写真に示す通り、ChatGPT がコメントで「普通に計算するとオーバーフローが起こるので、対数関数を使って計算します」と書いているところです。
ChatGPT は適当に正しいプログラムを書いたのではなく、よく注意してプログラムを書いていること、つまり注意力もあることがよく分かります。

第 9 問
いよいよ終盤になってきました。残る問題は 2 問です。
# Problem Statement There is a rabbit on 1D coordinate x. Rabbit will perform the following N operation. - 1st operation: Move to the position which is symmetrical with respect to coordinate A[1] - 2nd operation: Move to the position which is symmetrical with respect to coordinate A[2] - 3rd operation: Move to the position which is symmetrical with respect to coordinate A[3] - : - Nth operation: Move to the position which is symmetrical with respect to coordinate A[N] Write a program that outputs the coordinate of the rabbit after finishing all operations for x=1, 2, ..., K. # Constraints - 1 <= N <= 200000 - 1 <= K <= 200000 - 1 <= A[i] <= 1000000 (1 <= i <= N) - All input values are integer # Input N K A[1] A[2] ... A[N] # Output Print K lines. In i-th line (1 <= i <= K), print the answer when x=i. # Sample Input 3 2 5 3 9 # Sample Output 21 20
日本語の問題文は以下のようになります。
数直線上の座標 x にうさぎがいる。これから、うさぎは以下の N 回の操作を行う。
- 1 回目の操作: 座標 A[1] に関して対称な場所に移動する。
- 2 回目の操作: 座標 A[2] に関して対称な場所に移動する。
- :
- N 回目の操作: 座標 A[N] に関して対称な場所に移動する。
x=1, 2, ..., K について、すべての操作を終えた後のうさぎの座標を出力せよ。
この問題を解く方法を考えてみましょう。まず、座標 x にうさぎがいるとき、座標 target に関して対称な場所は 2*target-x となります。したがって、以下のようなプログラムを書くと、正しい答えが得られます。
# Input N, K = map(int, input().split()) A = list(map(int, input().split())) # Solve for x in range(1, K+1): position = x for target in A: position = 2 * target - position print(position)
しかし、このプログラムは二重ループになっており、およそ N×K 回の計算が必要になります。本問題の制約では、20 万掛ける 20 万すなわち 400 億回程度の計算が必要になるため、実行に 1 分以上かかってしまいます。
そこで「答えが x に関して一次関数になっている」という性質を使うと、プログラムを高速化することができます。実際、入力例では
- x=1 のときの答えが 21
- x=2 のときの答えが 20
- x=3 のときの答えが 19
- x=4 のときの答えが 18
という感じで一次関数的に減っていきます。ただし、この性質に気付くのは難しく、おそらく AtCoder の常連参加者でも 25% 程度の人しか気づかないと思います。
それでは、ChatGPT はこの問題を解くことができるのでしょうか。まず、ChatGPT は以下のようなプログラムを提出しました。計算回数的には問題ないものの、残念ながら解法が間違っており入力例で正しい答えを出力しないため、元も子もありません。
def compute_final_positions(N, K, A): # Calculate the cumulative effect of transformations total_shift = 0 for i in range(N): total_shift += 2 * A[i] # Prepare to output results for all initial positions from 1 to K results = [] for x in range(1, K + 1): # Final position after all transformations final_position = total_shift - N * x results.append(final_position) return results # Read input import sys input = sys.stdin.read data = input().split() N = int(data[0]) K = int(data[1]) A = list(map(int, data[2:])) # Calculate and print the result results = compute_final_positions(N, K, A) for result in results: print(result)
そこで ChatGPT に対してプログラムを修正するよう伝えましたが、
- 2 回目の提出:最初に書いたような「単純な実装のプログラム」を提出
- 3 回目の提出:1 回目の提出とほぼ同じ「間違ったプログラム」を提出
となり、残念ながら最後までこの問題を解くことができませんでした。
第 10 問
いよいよ最終問題です。
# Problem Statement There are N jewels in LLM Jewelry Shop. The jewels are numbered from 1 to N. The price of jewel i is P[i] dollars, and the weight of jewel i is W[i] grams. Mr.LLM wants to buy 2 jewels, but he is happy if the total price is 100 dollars or less, and the total weight is 100 grams or more. There are N(N-1)/2 possible ways of buying jewels, but how many of them are happy? Write a program that outputs the answer. # Constraints - 2 <= N <= 200000 - 1 <= P[i] <= 100 (1 <= i <= N) - 1 <= W[i] <= 100 (1 <= i <= N) - All input values are integer # Input N P[1] W[1] P[2] W[2] : P[N] W[N] # Output Print the answer. # Sample Input 5 30 30 60 40 50 50 40 60 70 60 # Sample Output 2
日本語の問題文は以下のようになります。
N 個の宝石がある。i 個目の宝石の価格は P[i] ドルで重さは W[i] グラムである。2 つの宝石を選ぶ方法は N(N-1)/2 通りあるが、その中で価格の合計が 100 ドル以下かつ重さの合計が 100 ドル以上のものは何通りあるか。
まず考えられる方法は、2 つの宝石の選び方を全探索する方法です。しかし、N の最大値は 20 万であるため、最大 200000×199999÷2 = 約 200 億通りを計算する必要があります。このままでは実行に時間がかかり、不正解となってしまいます。そこで以下のテクニックを組み合わせると、プログラムを高速化することができます。
- 価格と重さごとの個数を数えるという発想
- P[i], W[i] の制約が 100 以下であることを使う発想
- 累積和という典型テクニック
- 重複して数え上げないようにプログラムを書く注意力
かなり難しい問題です。AtCoder の常連参加者の中でも 20% 程度の人しか解けないと思います。
それでは、ChatGPT はこの問題を解くことができるのでしょうか。最初に提出したプログラムは次のようなものでした。
def count_happy_pairs(N, jewels): # Sort jewels by price jewels.sort() count = 0 # Use two pointers to find valid pairs for i in range(N): for j in range(i + 1, N): price_sum = jewels[i][0] + jewels[j][0] weight_sum = jewels[i][1] + jewels[j][1] if price_sum <= 100 and weight_sum >= 100: count += 1 return count # Read input import sys input = sys.stdin.read data = input().split() N = int(data[0]) jewels = [] for i in range(1, len(data), 2): P = int(data[i]) W = int(data[i + 1]) jewels.append((P, W)) # Calculate and print the result print(count_happy_pairs(N, jewels))
このプログラムは正しく動作しますが、残念ながら先程説明した「実行に時間がかかる解法」を実装したものであるため、不正解となります。そこで 3 章のマニュアル通り、以下のフィードバックを返します。
Unfortunately, your solution judged as Time Limit Exceeded. Please improve time complexity of your solution.
すると ChatGPT は次のようなプログラムを返してきました。無駄な探索をしない工夫が追加されているため、プログラムの実行時間は少し速くなりましたが、本質的にはまだ二重ループであるため実行に 1 分以上かかることには変わりありません。
import bisect def count_happy_pairs(N, jewels): # Sort jewels by price jewels.sort() count = 0 # Iterate through each jewel for i in range(N): price_i = jewels[i][0] weight_i = jewels[i][1] # Find the maximum price that the second jewel can have max_price = 100 - price_i # Use binary search to find the range of possible second jewels j_start = bisect.bisect_right(jewels, (max_price, 300), i + 1) for j in range(i + 1, j_start): price_j = jewels[j][0] weight_j = jewels[j][1] if price_i + price_j <= 100 and weight_i + weight_j >= 100: count += 1 return count # Read input import sys input = sys.stdin.read data = input().split() N = int(data[0]) jewels = [] for i in range(1, len(data), 2): P = int(data[i]) W = int(data[i + 1]) jewels.append((P, W)) # Calculate and print the result print(count_happy_pairs(N, jewels))
次は 3 回目、最後のチャンスです。マニュアル通りにフィードバックを送ります。果たして、ChatGPT は正しい解答を出すことができるのでしょうか。
import bisect def count_happy_pairs(N, jewels): # Sort jewels by price jewels.sort() # Extract prices and weights prices = [jewel[0] for jewel in jewels] weights = [jewel[1] for jewel in jewels] count = 0 # Iterate through each jewel for i in range(N): price_i = prices[i] weight_i = weights[i] # Find the maximum price that the second jewel can have max_price = 100 - price_i # Use binary search to find the range of possible second jewels j_start = bisect.bisect_right(prices, max_price, i + 1, N) for j in range(i + 1, j_start): price_j = prices[j] weight_j = weights[j] if price_i + price_j <= 100 and weight_i + weight_j >= 100: count += 1 return count # Read input import sys input = sys.stdin.read data = input().split() N = int(data[0]) jewels = [] for i in range(1, len(data), 2): P = int(data[i]) W = int(data[i + 1]) jewels.append((P, W)) # Calculate and print the result print(count_happy_pairs(N, jewels))
下の写真に示すように、コメントには「累積和を使う」という正しい発想が出てきました。しかし、惜しくもこれを実装することができず、実行時間制限超過で終わりました。

5. 実験結果のまとめ
長くなりましたが、ChatGPT が以上の 10 問を解いた結果は以下のようになりました。
| 問題 | 結果 | AtCoder のレーティング | AtCoder で解く割合5 |
|---|---|---|---|
| 第 1 問 | 〇 | 10 | 95% |
| 第 2 問 | 〇 | 30 | 85% |
| 第 3 問 | 〇 | 80 | 75% |
| 第 4 問 | 〇 | 130 | 70% |
| 第 5 問 | × | 150 | 70% |
| 第 6 問 | 〇 | 300 | 50% |
| 第 7 問 | 〇 | 500 | 40% |
| 第 8 問 | 〇 | 500 | 40% |
| 第 9 問 | × | 900 | 25% |
| 第 10 問 | × | 1000 | 20% |
したがって、人間の手助けが無い場合、ChatGPT の実力は茶色コーダー下位程度 (レーティング 400~599; AtCoder 常連参加者の上位 40~50% 程度) であると考えられます。6
ここで茶色レベルの参加者は、1 つ 1 つの基本的な解法テクニックは理解しているものの、複数の解法テクニックを上手く組み合わせられないという人が多いです。そのため、ChatGPT がさらに強くなるには、この壁を乗り越える必要があるのではないかと推測できます。
また、今回の結果は以下のように問題ジャンルによる差も見られました。7
- 第 6~7 問のような「典型的な問題」については茶色下位以上の実力がある
- 第 5 問のような「手を動かして解く問題」は苦手である
特に、AtCoder では主に以下の 2 種類のコンテストが開催されるのですが8、ChatGPT は同じ実力の参加者と比べて、前者が得意で後者が苦手ではないかと考えられます。
実際、ChatGPT が自身の実力を大きく上回る問題を解けた例として AtCoder Beginner Contest 345 D - Tiling が挙げられるのですが、この問題は典型的な全探索の問題であるため、傾向に当てはまっています。
実験結果に関する注意点
ここで、実験結果について注意しておかなければならないことが 2 つあります。1 つ目は、ChatGPT は今一番強い競プロ AI であるとは限らないということです。
たとえば 2023 年 11 月に Google が発表した「AlphaCode 2」という競プロ特化型の AI は、AtCoder では水色から青色程度 (上位 10% 以内) の実力を持つのではないかと言われています。
特化型 AI より汎用型 AI の方が当然不利であり、なおかつ AlphaCode は 100 万個のプログラムの候補をスパコンで生成したりするなど、潤沢な計算リソースを使用した AI であるため、無料の ChatGPT が負けるのは仕方ありません。
しかし、「世界で利用者数が最も多い AI のひとつである ChatGPT がこの程度の実力を持つ」というのが明らかになったことは、本実験において最も意義のあることだと思います。
2 つ目は、人間の手助けによって ChatGPT の実力が大幅に上がる可能性があるということです。たとえば人間が
- 具体的にここがバグっている
- 動的計画法を使えば解ける
などのアドバイスを与えると、これまで解けなかった問題が解ける可能性があります。例として第 5 問を振り返ってみましょう。第 5 問は最後無限ループに陥って不正解となりましたが、
next_valueにA[i-1]を足し続けているせいでnext_value % A[i-1]の値が絶対 0 にならなくてループから抜けない
ということを教えてあげた場合、解けた可能性がありました。また、惜しくも解けなかった第 10 問も、累積和を使うというアイデアを 1 回目の提出の前の時点で教えていれば、3 回のチャンスを使い切らずに解けた可能性がありました。
しかしながら、参加者の競プロの実力が高くなければ、的確なアドバイスを与えることはできません。そのため、実力の低い人が ChatGPT と人間の協力によって最上位の成績を取る、といったことは今の所現実的ではないと考えられます。
6. おわりに ~競プロの未来を見据えて~
最後に、茶色下位という結果はどう受け止めれば良いのでしょうか。人によって意見が分かれると思いますが、私の考えとしては、現時点ではそれほど大きな影響がないと思います。
例として就職・転職で AtCoder を使う場合を考えましょう。茶色のレーティングがあれば多少有利にはなりますが、急激に有利になり始めるのは一個上の緑色からです。そのため、ChatGPT を使って AtCoder に参加している人がまだ多くないことを考慮すると、大きな影響はありません。
ただし、筆者の考えとしては、もしプログラミング能力や思考力を上達させる目的で競技プログラミングに参加している場合、ChatGPT を使わずに問題を解くことをおすすめしています。なぜなら、自力でプログラムを書いた方が実力が上がりやすいと考えられるからです。
また、競プロを新たに始めた人が、ChatGPT に頼って参加している人に負けたなどの理由でモチベーションを落とす、といったことも考えられます9。しかし筆者としては、全く気にするべきではないと思います。なぜなら、もし全然プログラムが書けない人が ChatGPT に頼って実力以上の結果を取っても、本人にとっては何の力にもならないからです。
それでは、今後もし生成 AI がさらに強くなったら競プロはどうなるのでしょうか。
もちろん、競プロが続くかもしれないし、残念ながら終わってしまうかもしれません。どちらの可能性もあります。ですが将棋の場合、2017 年に人間のトップすら AI に破られたものの、まだ続いています。私の希望としては、将棋の例のように競プロが続いてほしいなと思っています。
最後になりますが、12,000 字超の長文を最後までお読みいただき誠にありがとうございました。
- https://openai.com/index/hello-gpt-4o/ 参照。↩
- 演算の種類によりますが、現代の PC では、毎秒 1~20 億回程度の演算ができることが多いです。↩
- インターネットの中には数万問の競プロの問題があるため、(特に典型問題に関しては) 内容がほぼ同じ問題が既に出題されている可能性があります。しかし少なくとも、問題設定はオリジナルになっています。↩
- アルゴリズムの教科書などに載っています。↩
- AtCoder Beginner Contest を想定。↩
- ただし、サンプル数が 10 と少ないため、この結果にはレーティング 400 程度の誤差を伴います。↩
- もちろん、10 問しか試していないので「有意差」と言えるほどの差はありません。↩
- その他にも AtCoder Grand Contest や AtCoder Heuristics Contest などがありますが、開催頻度は低いです。↩
- 現時点では ChatGPT を使っている人は高々数パーセントだと思っているので、それほど影響はないはずです。↩