「高校数学の基礎が150分でわかる本」にかけた思い
1. はじめに
こんにちは、東京大学 3 年の米田です。この度は、ダイヤモンド社から『高校数学の基礎が 150 分でわかる本』という書籍を出版させていただくことになりました。高校数学の基礎を図解で超わかりやすく説明した本です。
本稿では、この本を書いたきっかけや、この本に懸けた思いについて記したいと思います。
なお、本の内容紹介につきましては、以前こちらの記事に書かせていただいたので、まだ読んでいない方はぜひお読みください。

2. 前提:数学はあらゆる人が身に付けてほしい
執筆のきっかけについて書かせていただく前に、まずは数学に対する僕の考えを述べておきます。僕は、高校数学の基礎くらいのレベルの知識は、あらゆる日本人が身に付けるべきだと思っています。
この理由としては、仕事の幅が広がる、論理的思考力が身につくなどたくさんあるので、詳しくは発売日前後にブログにまとめようかと思慮しています。しかしその中でも代表的な理由の一つとしては、生活していくうえで便利であることが挙げられます。
以下に例を 3 つ示します。「どんな場面で数学が使えるのか」のイメージだけつかめれば大丈夫です。*1
例1:宝くじ (本の p.85 の類題)
ある宝くじを 1 枚買うのに 300 円かかります。当たりの賞金と確率が以下のとおりであるとき、宝くじを買うのは得ですか。損ですか。
- 1 等:賞金 1 万円/確率 1%
- 2 等:賞金 300 円/確率 20%
- 3 等:賞金 0 円 (ハズレ)/確率 79%
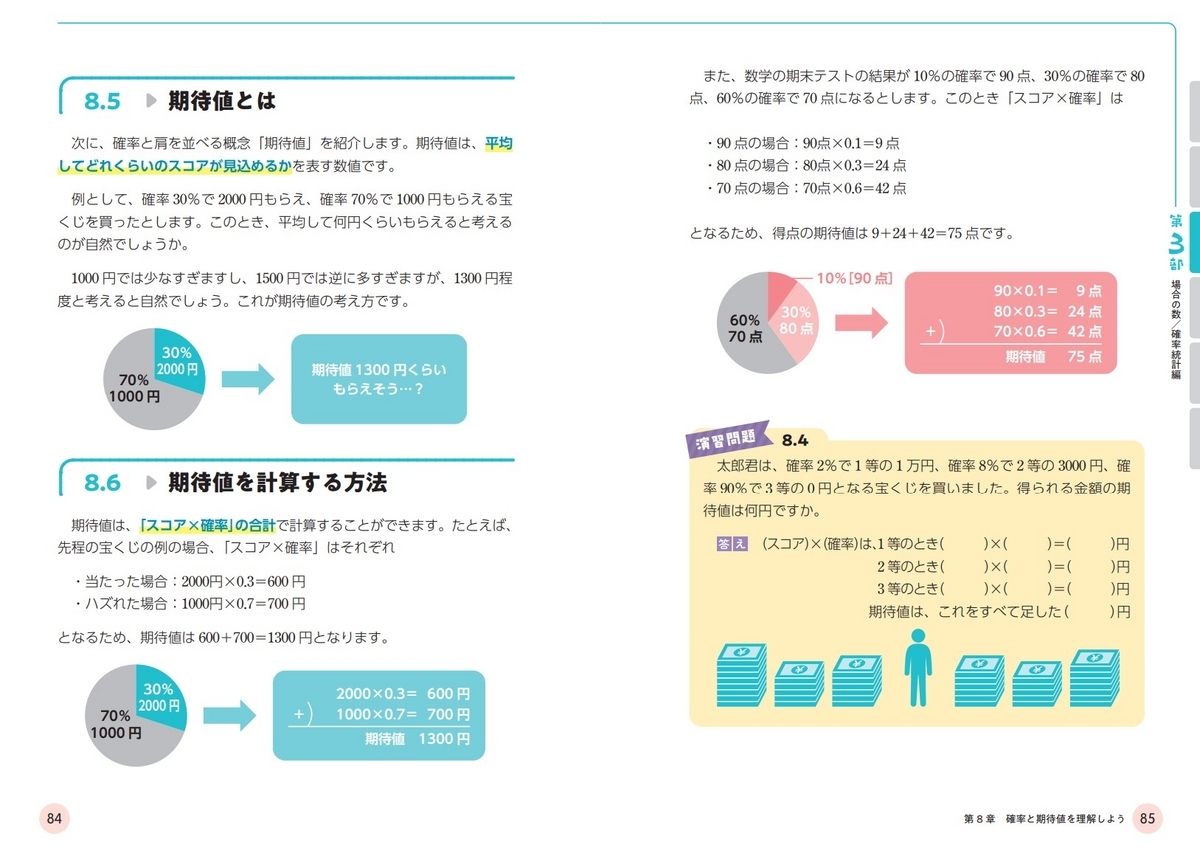
もし高校 1 年で習う「期待値」の計算方法を知っていれば、答えがわかります。
期待値を計算すると、平均して (10000×0.01) + (300×0.2) + (0×0.79) = 160 円の賞金しかもらえないとわかるので、この宝くじを買うのは損であると考えられます。
例2:データ分析 (本の p.96 の類題)
A 君と B 君の月別営業成績は以下の通りです。A 君と B 君のうちどちらが、安定した成績を出せていると考えられますか。*2
1月 2月 3月 4月 5月 A君 350万円 400万円 600万円 100万円 550万円 B君 300万円 250万円 750万円 500万円 200万円
もし高校 1 年で習う「標準偏差」の計算方法を知っていれば、答えがわかります。
計算過程は省略しますが、A 君の成績の標準偏差は約 176 万円、B 君の成績の標準偏差は約 202 万円であるため、A 君の方が安定しているといえます。*3
例3:投資 (本の p.55)
あなたは今 1000 万円を持っていて、上手く投資をすると年率 10%、つまり 1 年に 1.1 倍の割合で所持金を増やすことができます。このとき所持金は、
- 1 年後には 1000×1.1=1100 万円
- 2 年後には 1100×1.1=1210 万円
- 3 年後には 1210×1.1=1331 万円
と増えていきますが、果たして所持金が 10 倍の 1 億円になるのは何年後でしょうか。
もし高校 2 年で習う「対数 log」を知っていれば、答えがわかります。
答えは「1.1 を何乗すれば 10 になるか、つまり 」であり、これを電卓で計算すると約 24.15 なので、25 年後には 1 億円を超えている、ということが分かります。
このように、数学を学ぶメリットはたくさんあるため、僕は「高校数学の基礎」くらいの知識は、すべての日本人が身に付けるべきだとすら思っています。
3. 本書を執筆したきっかけ*4
しかし、数学に苦手意識がある人でも知識を身に付けられる本は、それほど多くありません。実際、僕がいくつかの本を読んだところ、国内で出版されている数学の本の多く(体感 9 割)は、残念ながら以下のいずれかに当てはまっています。
- 難しくてかなりの読者が脱落してしまう
- イラストや会話などの雰囲気でわかった気にはなるが結局身に付かない
そこで僕は、もしどちらにも当てはまらない最強にわかりやすい本を出版できれば、世の中の役に立てるのではないかと思いました。これが執筆を決めたきっかけです。
4. どう「わかりやすい本」を目指したか
ところが、前述のどちらにも当てはまらない、最強にわかりやすい本を書くのは全く簡単なことではありません。そこで拙著『高校数学の基礎が 150 分でわかる本』では、最強にわかりやすい本に仕上げるため、以下の 4 つの工夫を施しました。
- 250 個以上のフルカラーの図
- 数学が役立つたくさんの実用例
- 中学レベルの知識から丁寧に解説
- わかった気で終わらせない「穴埋め式演習問題」
なお、フルカラーの図については以下の紙面をご覧ください。図なしの見開きページがほぼ存在しないため、数学アレルギーの人でも抵抗感なく読み進めることができます。はじめて数学を学ぶ方、学び直しの方の 1 冊目の本として最適です。

5. おわりに - 本書はなぜ 200 ページか
最後に、本書を執筆する上で迷ったことを 1 つ記したいと思います。これはページ数をどれくらいにするかです。実際、本書の企画時には、大きく分けて以下の 2 つの選択肢がありました。
- 500 ページで、高校数学のほぼ全部をわかりやすく解説する(語りかける高校数学などが例)
- 200 ページで、高校数学の基礎に絞ってわかりやすく解説する
しかし長考の末、僕は後者の方を選ぶことにしました。なぜなら、本が長すぎると読む上での抵抗感が出てしまい、本来のターゲット層に届かなくなるのではないかと思ったからです。
ですので、本書は大体 3 時間程度で読めるようになっています。忙しいビジネスパーソンでも気軽に読めますので、興味のある方はぜひご購入ください。
本記事は以上です。最後までお読みいただきありがとうございました。大学の期末試験が迫る中、90 分で書いた乱文ですので、文章のクオリティはご容赦いただけると幸いです。
「高校数学の基礎が150分でわかる本」を書きました
1. はじめに
こんにちは、東京大学 3 年の米田と申します。この度は、ダイヤモンド社から『高校数学の基礎が 150 分でわかる本』という書籍を出版させていただくことになりました。高校数学の基礎を図解で超わかりやすく説明した本です。
発売日は 3 週間後の 2023/7/26 です。電子書籍版も同時期に出る予定です。本記事では、この本の内容や特徴について、簡単に紹介させていただきます。

2. この本はどういう本か
本書は、主に次のような方に向けた、高校数学の「超」入門書です。
- 高校数学をはじめて学ぶ方
- 数学を学び直したい方
日本ではたくさんの数学の本が毎週のように出版されています。しかしこの中の多くは、難しくて多数の人が挫折してしまうか、雰囲気でわかった気にはなるけど結局身に付かないかのいずれかです。
そこで本書は、そのどちらのパターンにも当てはまらない、最強にわかりやすい本を目指すため、以下の 4 つの特徴を備えました。
特徴1:「数式」よりも「フルカラーの図」
第一の特徴は、フルカラーの図が多いことです。
一般的な高校数学の本は、数式が多くて理解するのに時間がかかりますが、本書では「数式」よりも「フルカラーの図解」が多くなるように心掛けました。
その図の数ですが、なんと 250 個以上です。本書のページ数は 200 ページちょっとなので、毎ページに平均 1 個以上の図があることになります。

特徴2:中学数学からしっかりサポート
第二の特徴は、前提としている知識が少ないことです。
一般的な高校数学の本は中学数学の知識を前提としていますが、本書は「高校数学の基礎」を学ぶうえで必要な中学数学の知識もていねいに解説しているため、「もしかしたら中学数学も不安かも…」という方でも全然大丈夫です。(中学生でも読めることを目指しました)
実際、本書はマイナスの数とか文字式とか関数の基本とか、そういうところから始まっています。*1
特徴3:実用的な具体例が多い
第三の特徴は、数学が役立つ例が多いことです。
日本人が数学でつまづく原因の一つとして「数学がどう役立つかわからない」ことが挙げられますが、本書ではデータ分析・投資・電気料金・新規事業をはじめとする様々な具体例を取り上げているため、そんな心配は必要ありません。
特徴4:穴埋め式の演習問題
第四の特徴は、穴埋め式の演習問題があることです。
まず、数学の理解を「ふわっとした理解」で終わらせず、使えるレベルまで身に付けるには、問題を解くことが必要不可欠です。しかし問題が少しでも難しいと、挫折してしまう方も多いでしょう。
そこで本書の演習問題は、順に穴埋めしていくだけで簡単に解けてしまう形式にしました。以下に例を示します。

3. 本書のもう一つの特徴:気軽に読める
ここまでは本書がわかりやすい理由について説明してきましたが、本書にはもう 1 つの重要な特徴があります。これは「2~3 時間で読める*2」ということです。
高校数学の教科書は内容が多く、2 年生までの範囲に絞っても合計 800 ページ以上あります。さらに教科書というものは 1 ページにたくさんの内容を詰め込んでいるので、人によっては 1500 ページや 2000 ページと感じる方もいるでしょう。
一方、本書は「これだけは知っておかなければならない」という基礎に絞って約 200 ページで解説しました。そのため、大学受験などには向きませんが、部活で忙しい中高生、会社で忙しいビジネスパーソンであっても気軽に読むことができます。
はじめての方、学び直しの方の 1 冊目の本として最適です。
4. 本書で学べること
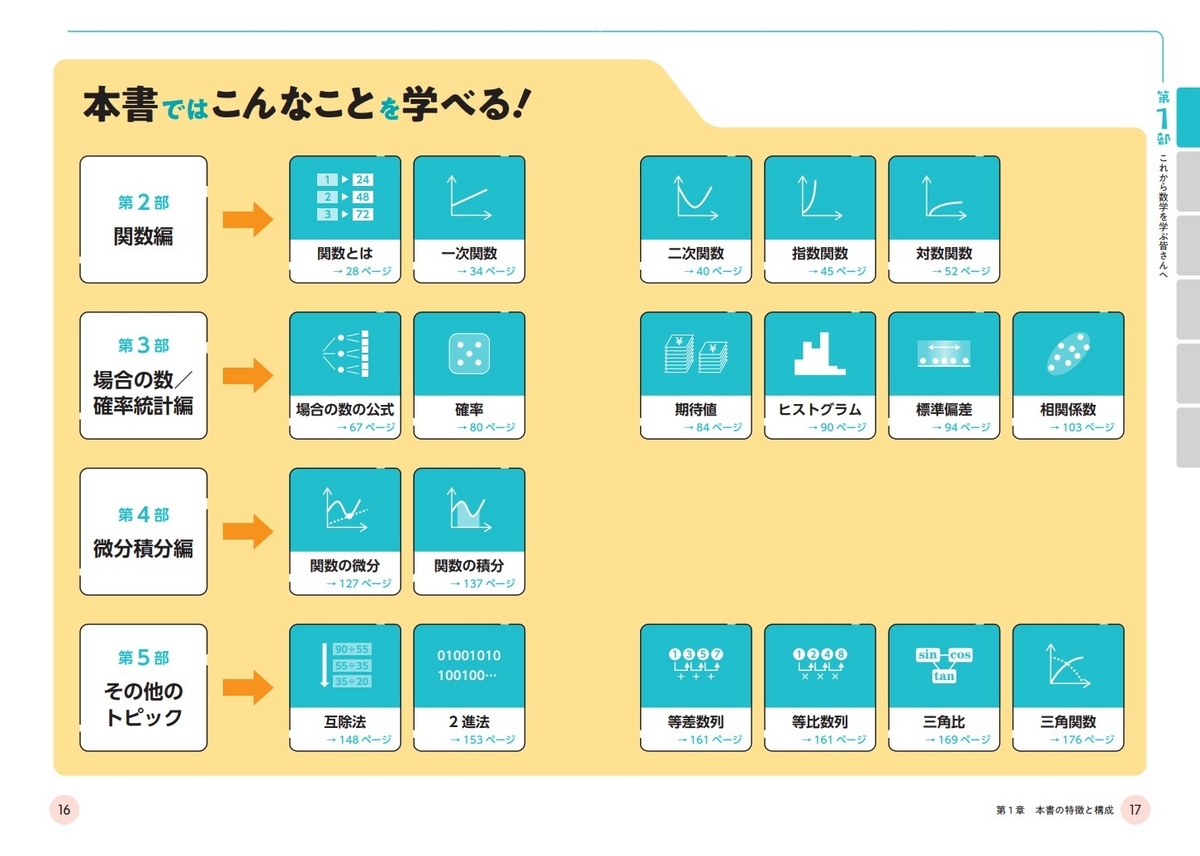
最後に、この本の内容について簡単に記させていただきます。本書では、
などの重要な知識を含め、下図のようなトピックを学ぶことができます。
※他にも、本の最初の方では前述したとおり、中学範囲の基礎知識 (文字式・累乗・ルートなど) も解説されています。
5. おわりに
実は、この本の出版依頼のメールが来たとき、受けるかどうかを 1 週間ほど迷っていました。もちろん過去に 2 冊のコンピュータ書を出した経験があるので本を完成させられる自信はあったのですが、さほど有名でもない私がこのような一般書を出して良いのかという悩みがありました。しかし、日本の教育や知識向上に少しでも役立てればという強い思いが最後の決め手になりました。
このこともあり、今回の本は「絶対に良い本を書かなければならない」という一心で執筆しました。まだ大学 3 年生の若造ではありますが、これまでの 21 年間の人生で得たものすべてを引き出し、どうすればわかりやすくなるのか、どうすれば 1 人でも多くの人に内容を理解させることができるのかを真剣に考えて執筆しました。
ですので、読んだ人には絶対に後悔だけはさせません。
それでは、ぜひ「高校数学の基礎が 150 分でわかる本」をお読みください。
『競技プログラミングの鉄則』序盤20,000文字+目次を無料公開します!
はじめに
こんにちは、東京大学 2 年の米田優峻(@e869120)です。先日、私はマイナビ出版から『競技プログラミングの鉄則』という本を出版しました。競技プログラミング(競プロ)でも使えるアルゴリズムの知識や、思考力を身に付けることができる全く新しい教科書です。
そして大変ありがたいことに多くの方々に読まれており、発売 4 日後に重版、発売 1 カ月後に再重版が決定しました。そして Amazon では 2022/10/30 時点で平均 ★4.9 という、身に余る程の評価をいただいております(ありがとうございます!)。
そこで、発売・重版を記念して、本書の「目次部分」と「序章・第 1 章」を無料公開します(全部で 2 万字超)。精魂込めて本を執筆しましたので、ぜひその一端を体験していただけると嬉しいです。

『競技プログラミングの鉄則』無料公開
ブログに直接打ち込んでも良いのですが、フルカラーの図がとても多いので、見やすさを重視して PDF で公開することにします。リンクは以下の通りです。
最後になりますが、もし無料公開部分を読んで興味を持っていただいたのであれば、ぜひ本全体をお読みいただければと思います。なお、本書の詳しい特徴につきましては、以下の記事にまとめられています。